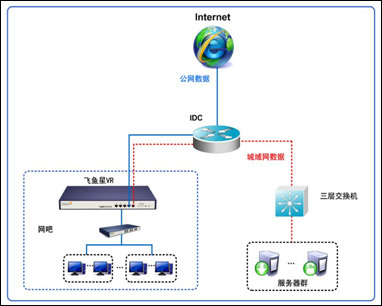
在網絡服務領域中,“不含互聯網資源協作服務”與“僅限互聯網資源協作服務”是兩種截然不同的服務模式,它們在服務內容、功能范圍和技術實現上存在顯著區別。理解這些區別對于企業和個人用戶選擇合適的網絡服務至關重要。
一、核心定義與概念辨析
1. 不含互聯網資源協作服務
這種服務模式通常指的是網絡服務提供商不提供任何與互聯網資源協作相關的功能。例如,傳統的虛擬專用服務器(VPS)、獨立服務器或部分基礎云服務,主要側重于提供計算、存儲和網絡連接等基礎設施,而不包含文件共享、協同編輯、在線項目管理等協作工具。用戶需要自行搭建或集成第三方協作平臺。
2. 僅限互聯網資源協作服務
這種服務模式則專門提供互聯網資源協作功能,但不包含其他網絡服務。例如,在線文檔編輯工具(如Google Docs)、項目管理軟件(如Trello)或團隊溝通平臺(如Slack),它們專注于幫助用戶通過互聯網進行協作,但通常不提供服務器托管、網站建設等基礎網絡服務。
二、主要區別對比
- 服務內容與功能
- 不含互聯網資源協作服務:以基礎設施為核心,強調計算能力、存儲空間、網絡帶寬和安全性。用戶需要自行管理操作系統、應用程序和數據,協作功能需額外配置。
- 僅限互聯網資源協作服務:以協作工具為核心,提供實時溝通、文件共享、任務分配和進度跟蹤等功能,用戶無需關心底層技術細節。
- 技術實現方式
- 不含互聯網資源協作服務:通常基于虛擬化技術或物理硬件,用戶擁有較高的控制權,但需要一定的技術能力進行維護。
- 僅限互聯網資源協作服務:多采用軟件即服務(SaaS)模式,通過瀏覽器或輕量級客戶端訪問,由服務商負責技術維護和更新。
- 適用場景
- 不含互聯網資源協作服務:適用于需要高度定制化環境的企業,如軟件開發、大數據分析或特定行業應用,協作需求可通過獨立系統滿足。
- 僅限互聯網資源協作服務:適用于團隊協作頻繁的場景,如遠程辦公、跨部門項目或教育合作,強調便捷性和即時性。
- 成本與資源投入
- 不含互聯網資源協作服務:用戶需支付基礎設施費用,并可能承擔協作工具的額外成本和技術人力投入。
- 僅限互聯網資源協作服務:通常按用戶數或功能訂閱收費,初期投入較低,但長期使用可能產生持續費用。
三、實際應用案例
- 不含互聯網資源協作服務:某游戲公司租用云服務器運行游戲后端,但使用獨立的內部系統進行團隊任務管理。
- 僅限互聯網資源協作服務:一家咨詢公司全員使用在線會議和文檔平臺處理客戶項目,無需自建服務器。
四、選擇建議與趨勢
隨著云計算和遠程辦公的普及,許多網絡服務提供商開始融合兩種模式,例如提供基礎設施的同時集成協作工具(如AWS與Slack的整合)。用戶應根據自身需求評估:
- 如果技術能力強且需要高度控制,可選擇“不含互聯網資源協作服務”并搭配專業協作軟件。
- 如果追求效率和易用性,且協作是核心需求,“僅限互聯網資源協作服務”可能更合適。
- 混合模式也逐漸成為趨勢,結合基礎設施的穩定性與協作工具的靈活性。
這兩種服務模式并非對立,而是網絡服務生態中的不同組成部分。明確區別有助于優化資源配置,提升工作效率,推動數字化轉型。